

为什么选择 Xilinx AI
最高计算效率和最佳性能
世界首个零暗人工智能芯片
虽然许多 AI 芯片均声称有数百个 TOPS,但大多数只能达到峰值性能的 40%,有一半以上的暗(未使用的)硅。AMD-Xilinx 实现了 90% 的全球最高计算效率,成为首家在现代 AI 基准测试中实现接近零暗 AI 芯片的供应商。
")
最佳 AI 推断性能
从边缘到数据中心的业界最高级 AI 加速。最高的 AI 推断性能,最快的体验和最低的成本。

面向数据中心的 AI
以最低时延实现最高吞吐量,从而可加速云端图像处理、语音识别、推荐系统加速以及自然语言处理 (NLP) 加速

面向边缘的 AI
卓越的 AI 推断功能,可加速在自动驾驶汽车、ADAS、医疗保健、智慧城市、零售、机器人以及边缘自主机器中的深度学习处理。
限时特惠与 AI 网络研讨会
.jpg)

数据中心 AI 加速
高吞吐量 AI 推断

高性能 AI 推断
与主流 GPU 相比,TCO 提升 1 倍
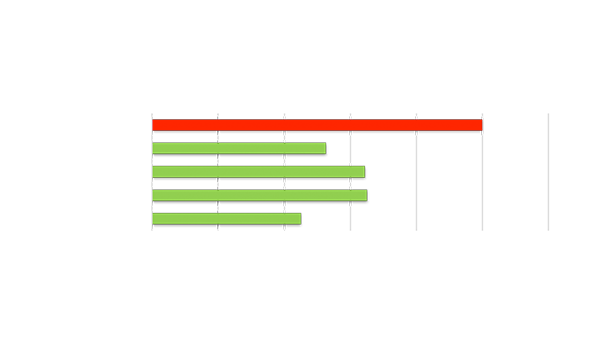

最高性能的视频分析吞吐量
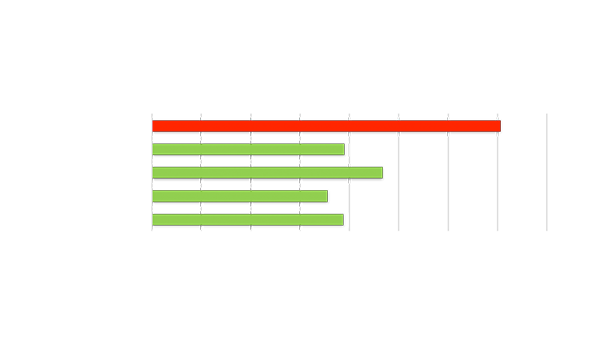
与主流 GPU 相比,视频流数量增加 1 倍
")
简易学习曲线
不需要硬件编程的普及型 AI 模型和框架

图源:https://developer.Nvidia.com/deep-learning-performance-training-inference
Xilinx 数据中心 AI 案例研究



使用 Xilinx 数据中心 AI 解决方案启动设计



购买 VCK5000
为在 Xilinx 7nm Versal ACAP 上构建的 AI 推断购买 VCK5000 开发卡
试用我们的合作伙伴解决方案
使用 Mipsology 执行高性能 AI 推断计算,使用 Aupera 为 AI 识别实现全视频处理 ML 推断流水线
下载 Vitis AI
使用 Xilinx AI 解决方案启动设计并下载 Vitis™ AI 开发环境
边缘 AI 加速
业界领先的 AI 加速性能

具有最低时延的 AI 推断
- Zynq® UltraScale+ 及 Versal® 上的最佳 FPS 和功耗
- 强大的深度学习处理单元 (DPU)
- 业界一流的模型优化技术;5 倍至 50 倍的模型性能提升

灵活的软件流程
- 支持 PyTorch、TensorFlow 和 Caffe 的 AI 模型
- 基于 C++ 和 Python 的简单库和 API
- 支持跨边缘平台部署的统一量化器、编译器和运行时

可扩展与灵活应变
- 可扩展的 DPU IP 适用于不同的逻辑和 AIE 资源
- 开放式 AI 模型专区,可在开发板上免费试用
- 整体应用加速
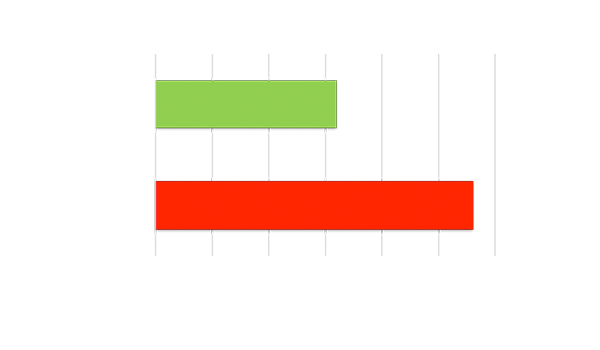
时延响应对比

高吞吐量或低时延
使用大批量规模实现吞吐量。在处理之前必须等待所有输入就绪,从而导致高时延。

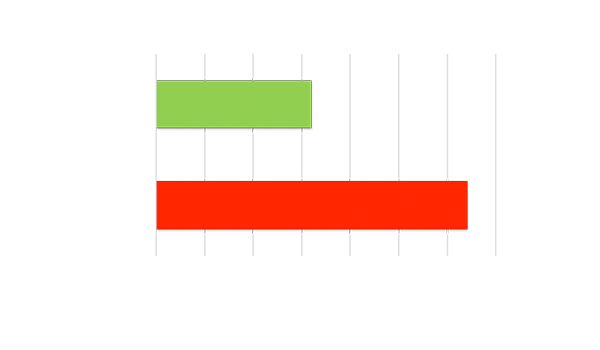
高吞吐量与低时延
使用小批量规模实现吞吐量。在每个输入就绪时立即处理,从而降低时延。
适合所有边缘产品的可扩展性

端到端应用性能
将自定义加速器紧密耦合在动态架构芯片器件中,优化了 AI 推断以及其它性能关键型功能的硬件加速。
这提供的端到端应用性能明显高于固定架构 AI 加速器。在该器件中,没有自定义硬件加速的性能或效率,应用的其它性能关键型功能仍然必须在软件中运行。


利用 Xilinx 边缘 AI 解决方案开始设计



购买 Kria KV260 视觉 AI 入门套件
针对高级视觉应用开发构建,无需复杂的硬件设计知识
下载 Vitis AI
使用 Vitis AI 在应用的边缘设备上实现高效的 AI 计算
访问 Xilinx 应用商城
Kria 系统级模块 (SOM) 的预构建应用评估、购买和部署加速应用!
探索 Xilinx 的边缘 AI 推断解决方案




开发者资源

访问 Xilinx 应用商城
评估、购买和部署加速应用!

开发者网站
仔细研究技术文章、项目和教程等!

及时了解最新信息
关注所有有关 AI 加速的新闻