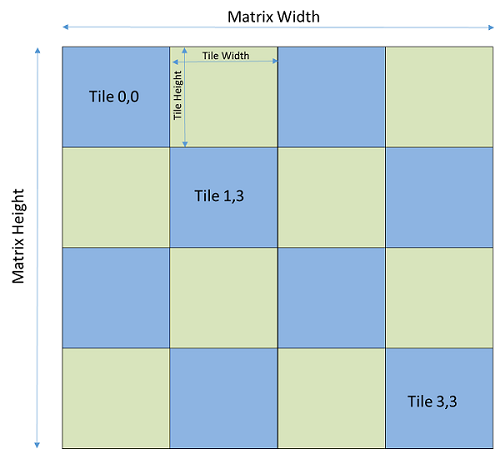
Some applications like very large matrix multiplications process large amount of
data that cannot all be brought into the local memory at once for fast access. It is
more practical and efficient to divide the data into tiles and read/compute/write one
tile of data at a time. The figure below shows a square matrix divided into 16 tiles
with equal size.
Figure: Matrix Divided into 16 Tiles
Below is the code snippet from the Window of 2D Array Example Using AXI4-Master Interface
Example in “kernel_to_gmem” category on Xilinx On-boarding Example GitHub that shows
the recommended coding style for inferring burst read and write of tiles of data from a
two dimensional array (e.g. matrix). Note that the data from the global memory
inx is read consecutively into the local memory
tile in the innermost loop. Also note that the innermost loop is
pipelined using the xcl_pipeline_loop
attribute.
kernel __attribute__ ((reqd_work_group_size(1, 1, 1)))
void read_data(__global int *inx) {
int tile[TILE_HEIGHT][TILE_WIDTH];
rd_loop_i: for(int i = 0; i < TILE_PER_COLUMN; ++i) {
rd_loop_j: for (int j = 0; j < TILE_PER_ROW; ++j) {
rd_buf_loop_m: for (int m = 0; m < TILE_HEIGHT; ++m) {
__attribute__((xcl_pipeline_loop))
rd_buf_loop_n: for (int n = 0; n < TILE_WIDTH; ++n) {
// should burst TILE_WIDTH in WORD beat
tile[m][n] = inx[TILE_HEIGHT*TILE_PER_ROW*TILE_WIDTH*i+TILE_PER_ROW*TILE_WIDTH*m+TILE_WIDTH*j+n];
}
}
rd_loop_m: for (int m = 0; m < TILE_HEIGHT; ++m) {
__attribute__((xcl_pipeline_loop))
rd_loop_n: for (int n = 0; n < TILE_WIDTH; ++n) {
write_pipe_block(inFifo, &tile[m][n]);
}
}
}
}